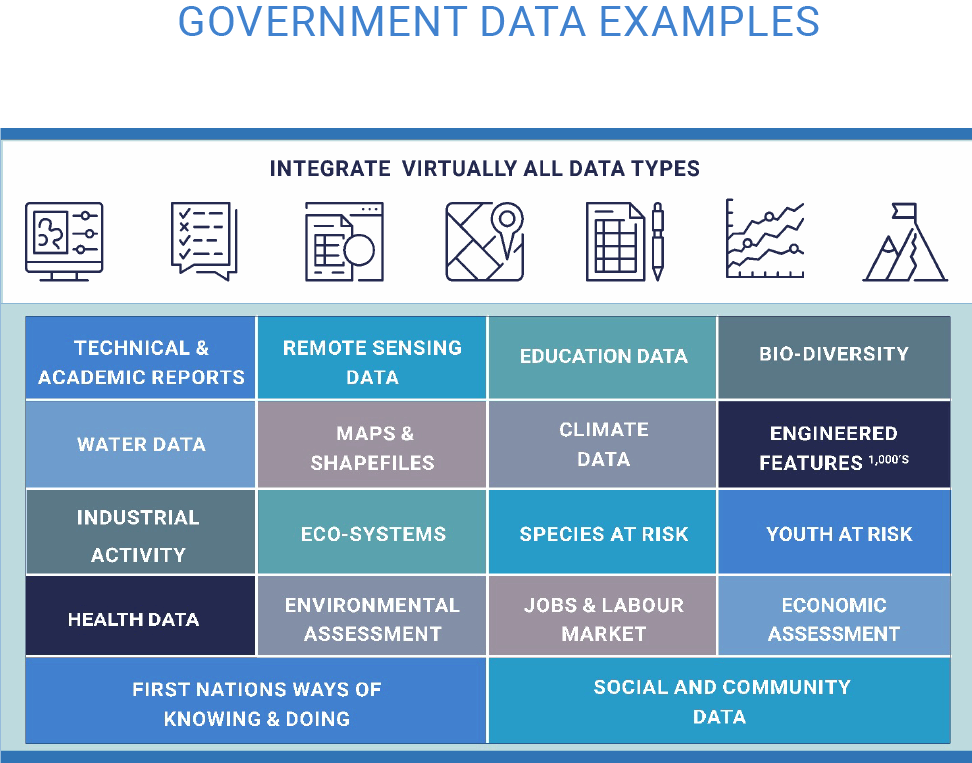
Advanced analytics foundation
Our Knowledge Repository
Key to enabling Advanced Analytics
Key to enabling Advanced Analytics
The value of advanced analytics is highly dependent on the depth of information extraction and integration that can be derived from the data. One of the key benefits of natural language processing models (NLP), is the understanding of subjects— for example “Place Names” or “Commodities”. Our NLP models can extract subjects from text and table-based information. Unlocking new insights from static texts can provide an entirely new set of features to use in further analysis.
NLP can provide insights into the distribution of features within the data, and extract and embed the underlying knowledge into a highly refined data architecture.
A Knowledge Repository is not a duplication of data—it is an extraction of relevant context specific information, which is then embedded into a complex set of feature attributes across all data sets. The result an integrated repository of knowledge.
From Warehouses… And Data Centres, And Data Lakes… To An Integrated Knowledge Repository
Key to Enabling Advanced Analytics
A Knowledge Repository is not a duplication of data—it is an extraction of relevant information attributes and features, which are then embedded and classified into a complex set of associations and correlations across other integrated data.
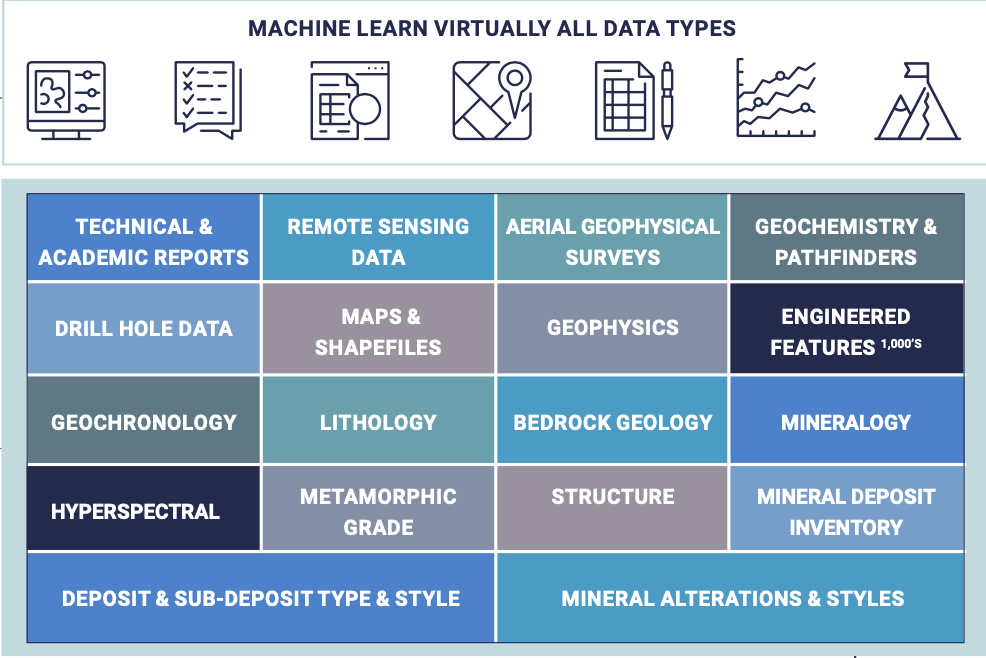
Resource Exploration Data Type Example
As data moves through our NLP models, the platform’s different processes transform engineered or extracted features into relevant data attributes (Data Architecture Features), this extracted data is then run through analytic processes that builds a persistent map of the correlations across every data point embedded into the system and held persistently. This analytic processing, is a key reason why our analytics is so lightning fast. We’ve done a large chunk of the analytics upfront.
Platform visuals
Knowledge repository interface